当你是OpenAI这样的公司,运行着像ChatGPT这样的尖端AI模型时,你需要的基础设施必须达到超级计算机的水平。将Kubernetes扩展到庞大的7,500个节点?这绝非易事。这种规模背后的关键在于,用Flannel(一种广泛使用的网络插件)替换为Azure CNI——一种与微软Azure生态系统紧密集成的解决方案。
分类目录归档:云运维
华山论剑:宽带之争 ▎F5G全光网络 vs 以太全光网络
无源光网络(PON:Passive Optical Network)技术在FTTH光纤到户场景,已经被证明是最经济高效和低碳节能的光纤接入技术,在全球拥有7亿级的用户接入量。
F5G全光网络采用XGS-PON/GPON无源光网络技术,拥有大带宽、低时延、安全可靠、绿色环保和多网融合等优势,在2019年将应用场景延伸到政企园区接入场景,并以迅雷不及掩耳之势,掀起了一阵全光网络建设热潮。以太厂商也纷纷推出以太全光方案,加入全光阵营。
那么问题来了,园区的最佳全光网络方案,到底是F5G全光网络,还是以太全光网络呢?以太全光厂商经常说F5G全光是共享带宽机制,采用分光器分光,把带宽都均分了,会导致每个终端的带宽不足,这是真的吗?F5G全光方案东西流量互访有问题,这是真的吗?以太全光宣称是独享带宽,这是真的吗?让我们擦亮眼睛一起辨别一下,客观公正地来寻找答案。
♢ F5G分光科普 ♢
无源分光器是F5G全光网络的基础部件,无源是指无需电源供电即可工作,分光是指光信号经过分光器之后,可输出多份相同的光信号,每一份光信号内容都一样,只是光信号功率强度变弱了。如下示例,光信号功率强度为2dbm的输入光信号,经过1:16等比分光器之后,变成光信号功率强度为-12dbm的光信号,其中1:16等比分光器的典型光功率损耗约14db。
注:1:16等比分光,每一支路输出的光功率强度为原来的1/16,即强度比原来小10log(1/16)≈12db,加上其它损耗约14db。
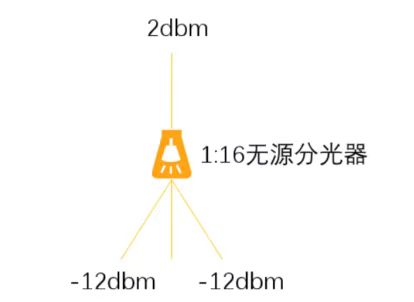
由分光器分光的物理本质可以知道,PON口发送的光信号,经过分光器之后,每一个ONU都可以接收到相同的光信号,分光器均分PON口带宽的说法显然是错误的,每一个ONU都可以达到PON口的最大带宽。
♢ 带宽架构 ♢
F5G全光点到多点无源分光 VS 以太点到点有源分光
首先,从架构本质入手,两种全光方案架构本质的核心差异如下图
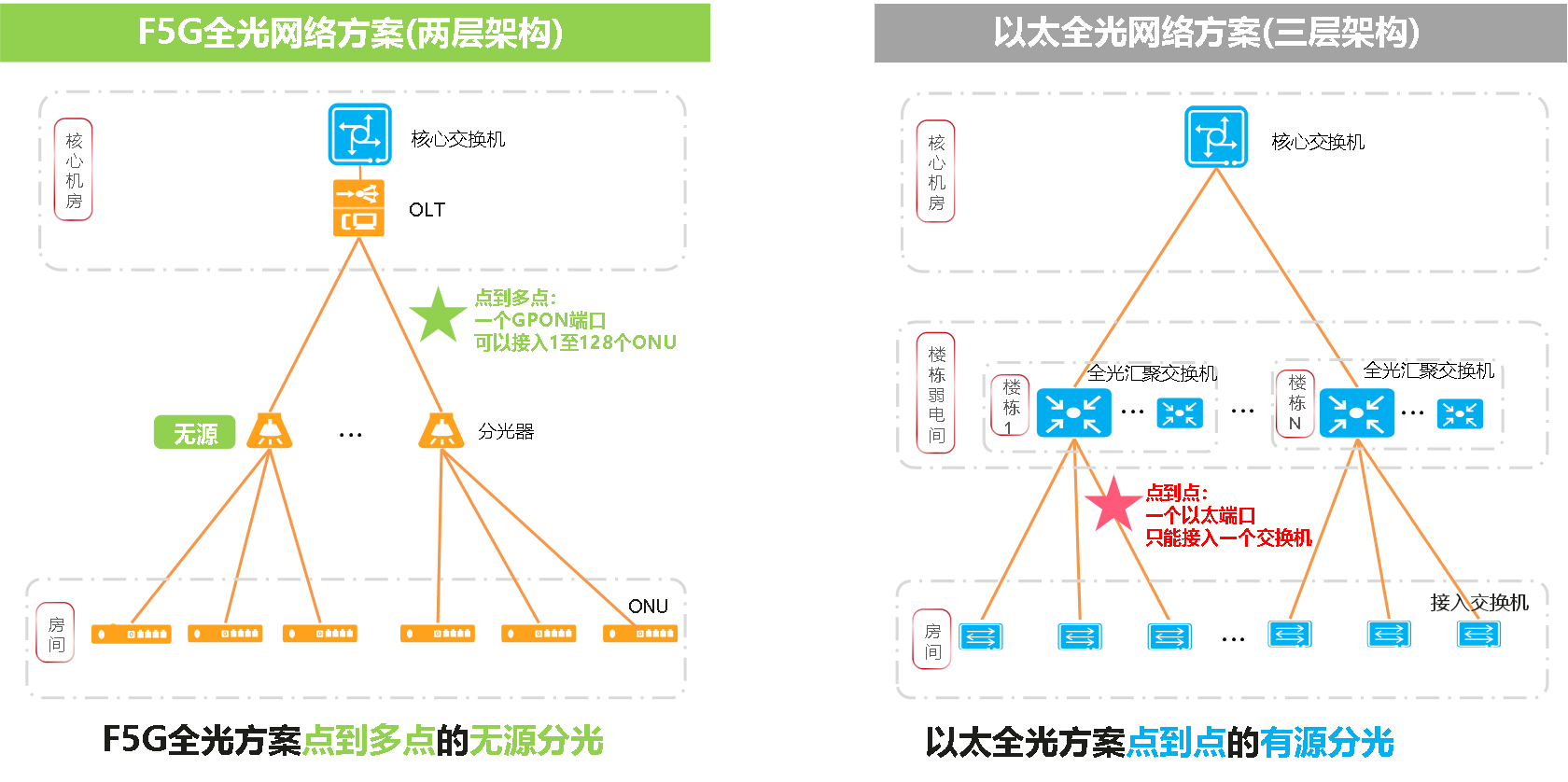
F5G全光网络采用点到多点的无源分光技术,一个PON端口可通过无源分光器接入1至128个ONU,是点到多点的连接。无源分光器的引入,实现了园区极简的两层架构。OLT可部署在核心机房,无源免维护的分光器则可部署在园区的任意位置,ONU部署在房间。
以太全光网络和传统网络一样仍然是三层架构,只是将楼层弱电间的接入交换机,在端口数量变少之后,下沉到房间,但仍需要在楼栋弱电间部署大量有源的汇聚交换机。也许有人会问,如果把汇聚交换机和OLT一样部署在核心机房,那么以太全光方案不也可以实现两层架构吗?这得铺多少根光纤、占用多粗的光纤管道(思考一下为什么?),才能把接入交换机的光纤全部拉到核心机房。本质上,以太全光是点到点的有源分光技术。为什么这么说呢?汇聚交换机的上行口实际对应于无源分光器的上行口,汇聚交换机的接入端口对应于无源分光器接入端口,汇聚交换机需要供电,这不就是有源分光嘛。至于点到点,这个很容易理解,一个汇聚交换机的端口只能接入一个接入交换机,是点到点连接。
♢ 带宽模型:本质收敛 ♢
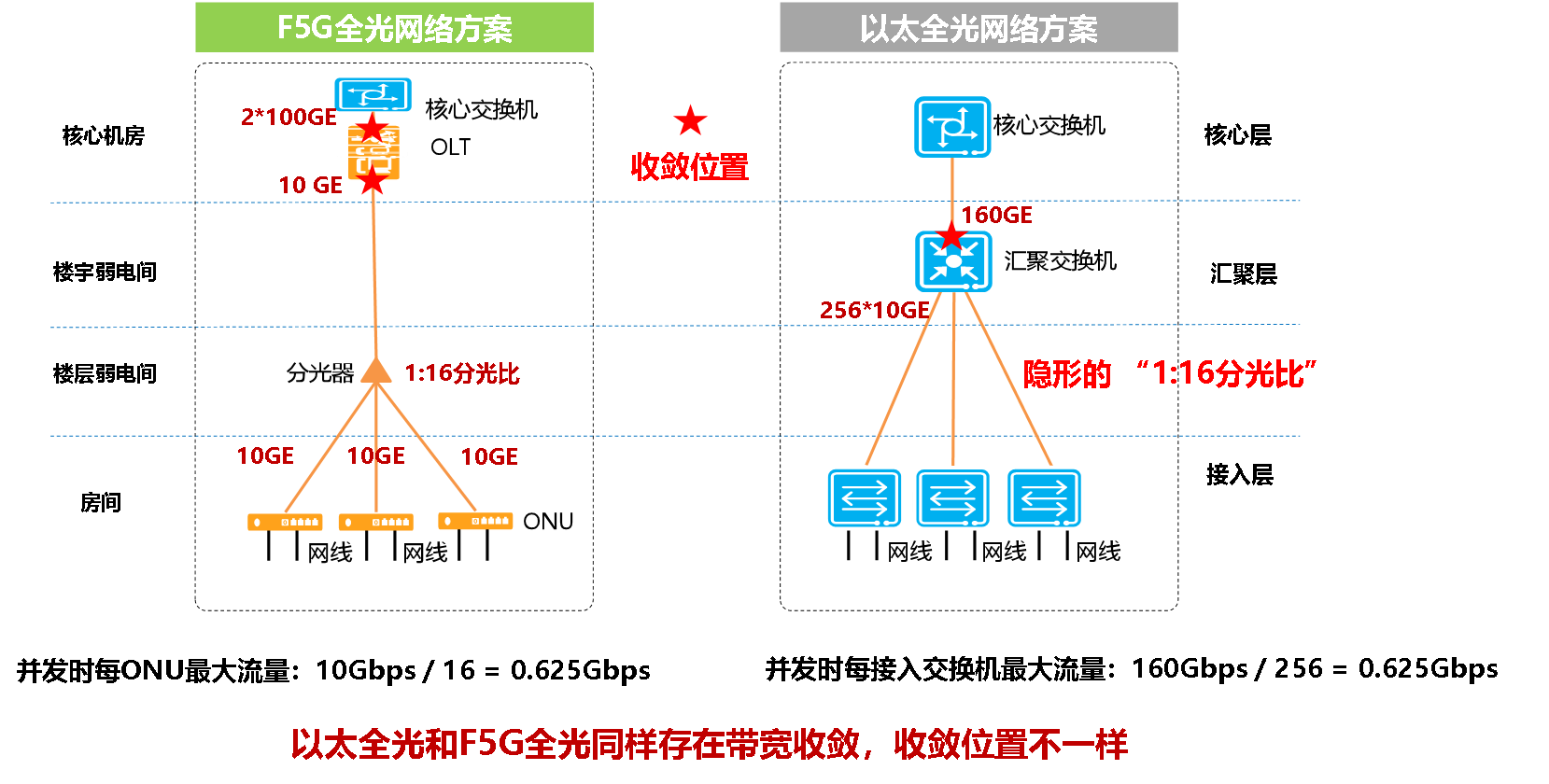
回到前文提到的问题,F5G是共享带宽,以太全光是独享带宽,这是真的吗?让我们从带宽模型角度来分析一下,如下图,F5G全光和以太全光都存在带宽收敛,只是带宽收敛的位置不一样而已,实质上都是共享带宽。例如:F5G全光方案采用XGS-PON(10G GPON)技术,采用1:16的分光比,收敛比是1:16。以太全光方案采用160GE的上行,用户侧接入256个10GE接入交换机,收敛比也是1:16。
♢ 南北流量:平分秋色 ♢
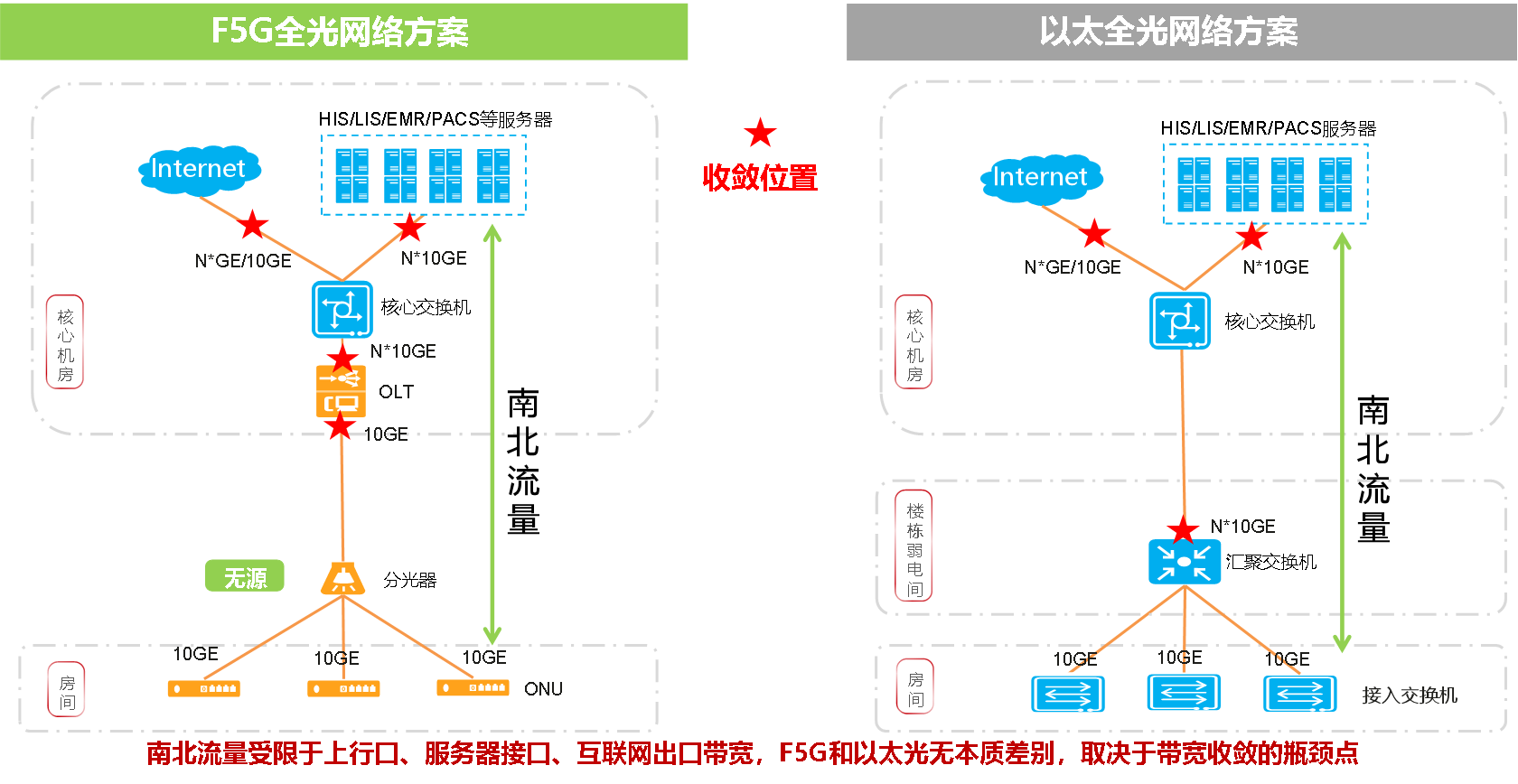
随着园区业务云化和集中化的趋势,核心业务系统主要部署在核心机房的数据中心或云上,而终端用户访问和使用这些业务均属于南北流量。南北流量在整个园区网络中存在多处收敛点,PON端口的分光器的收敛,只不过是众多收敛点中的其中一个,绝不是瓶颈。以太全光方案的带宽收敛点在于汇聚交换机上行端口。南北流量业务,所以F5G全光和以太全光并无本质差别,只是带宽收敛位置不一样而已。
♢ 东西流量:各有千秋 ♢
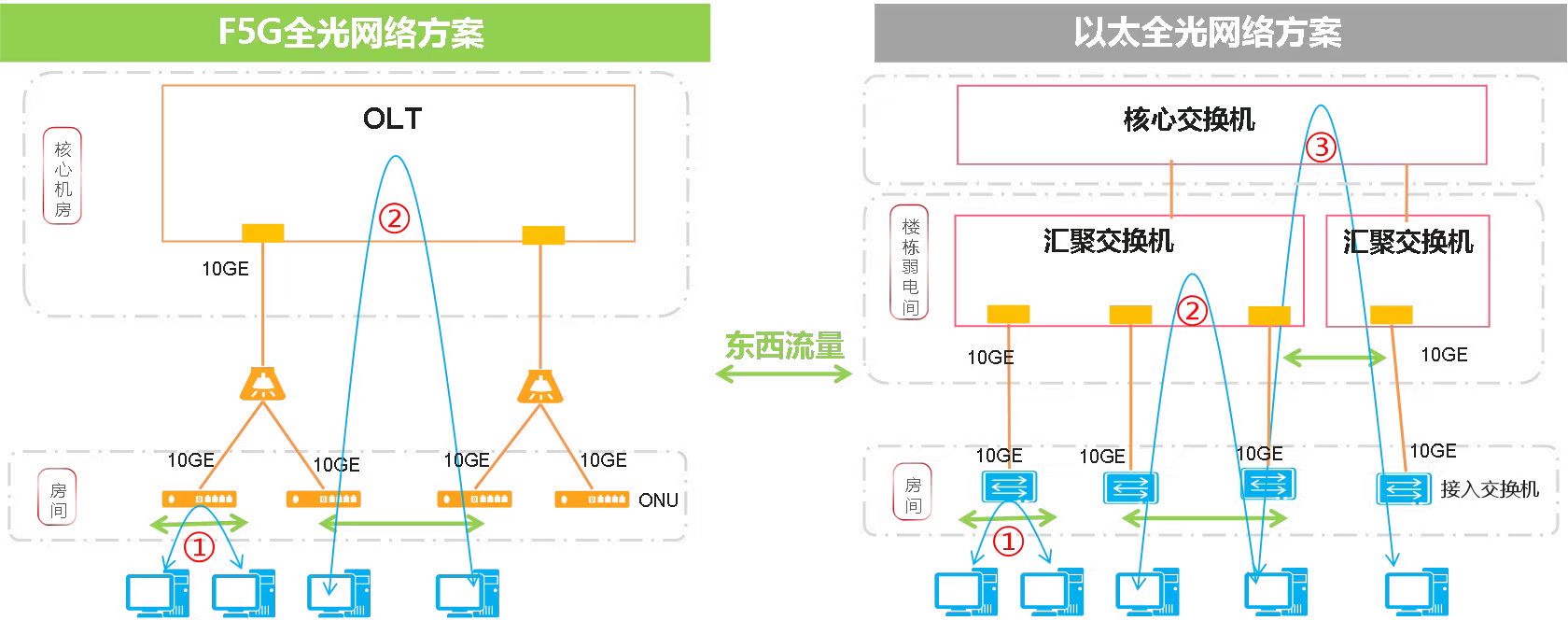
东西流量分为三个互通场景:
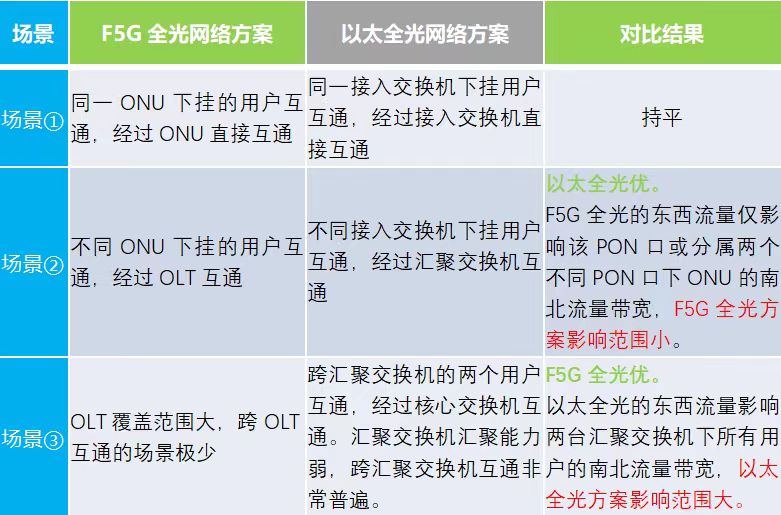
◆场景①:同一ONU或者接入交换机下挂的用户互通。F5G全光方案可以在ONU内部进行不同用户的互通。以太全光方案可以在接入交换机内部进行不同用户的互通。两者无差别。
◆场景②:在一台OLT不同ONU下挂的用户互通,或者一台汇聚交换机下接入交换机下挂的用户互通。F5G全光方案可以在OLT内部进行不同用户的互通。当这两个用户在同一个PON口时,这两个用户的互通流量只影响该PON口下其它用户的南北流量带宽。当这两个用户在不同PON口时,这两个用户的互通流量会影响两个PON口下的其它用户的南北流量带宽。以太全光方案在一台汇聚交换机下挂的用户互通,因为汇聚交换机和接入交换机之间是独享链路的原因,此时不影响其它用户,该场景以太全光优。
◆场景③:不同汇聚交换机下挂用户的互通。不同汇聚交换机下挂的用户互通,互通的流量都需要经过汇聚交换机的上行口,到核心交换机进行互通,互通流量占用汇聚交换机的上行口带宽,此时互通的流量会影响整个汇聚交换机下所有用户的南北流量带宽。
场景3只考虑以太全光方案,是因为F5G全光方案中一台OLT可接入用户数非常多,跨OLT互通的场景在实际应用中非常少见。而以太全光方案中一台汇聚交换机可接入用户数少,跨汇聚交换机互通的场景更为普遍。
A. F5G全光方案,OLT上一块16口的PON板,通过1:16分光技术,就可以接入256台ONU,一台OLT可接入17 PON板 * 256 ONU = 4352台ONU,基本上一个中大型园区,只需要一台OLT放置在核心机房就可以覆盖整个园区的用户接入了
B. 以太全光方案,若采用框式汇聚交换机,一块单板按48端口计算,按业界一般可插8块单板的汇聚交换机计算,只能接入384台接入交换机(实际上,还需要预留1块或2块单板槽位做上行板,此时就只能接入288台接入交换机)。若采用盒式汇聚交换机,则最多只能接入48台接入交换机。楼栋弱电间需要部署多台汇聚交换机才能满足楼栋接入要求。由于1台汇聚交换机汇聚接入用户少,跨汇聚交换机(楼栋内、楼栋间)互通,对于以太全光来说,是一个非常普遍的情况。
东西流量对比总结如下:
划重点:东西流量一般只有在电脑共享文件夹,或者用户私搭FTP服务器等场景,才会直接出现东西流量互访,这种互访方式由于不受安全监管控制,容易存在信息泄露等安全性问题。
♢ 灵魂拷问 ♢
以太光的接入段带宽独享还有实际应用场景吗?
重要事情说三遍:以太全光的独享仅限于
接入段!接入段!接入段!
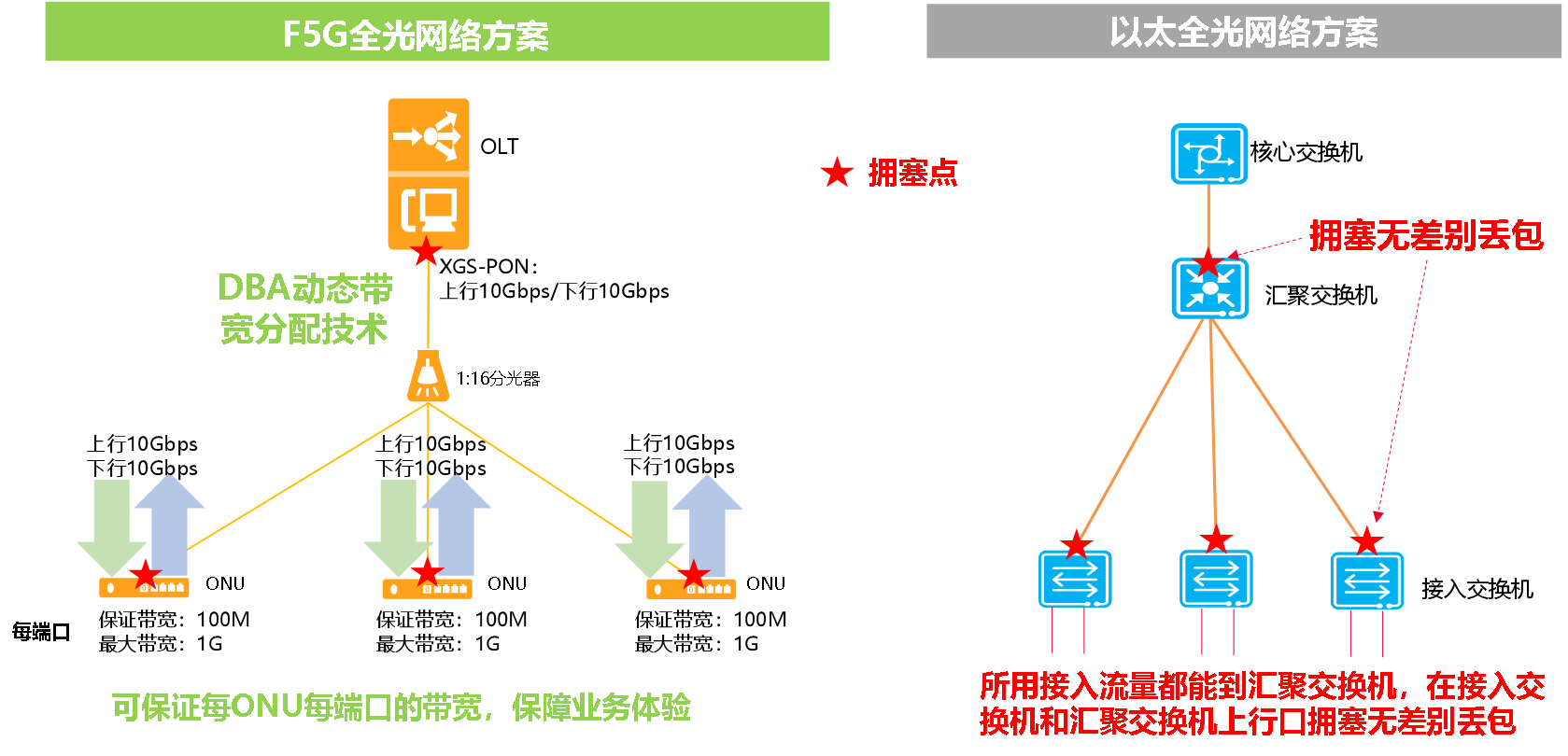
F5G全光方案分光器不分带宽,分光器只是分配光功率,每个ONU均可以达到PON口的最大带宽(XGS-PON 10Gbps或GPON 2.5Gbps)。F5G全光方案通过芯片级的动态带宽保证技术,可以保证每个ONU的每个端口都有确定性的保证流量,即使网络拥塞,这部分带宽也是可保证的,不会出现网络卡顿。
以太全光方案,由于没有带宽保证机制,在接入交换机的上行口拥塞和汇聚交换机的上行口拥塞,都会产生无差别丢包。举个简单的例子,有一台GE上行的接入交换机,下行4个GE接入4台电脑。当其中一台电脑,以接近1Gbps的速率往服务器上传文件时,其它3台电脑就连浏览普通网页都会感觉到无比卡顿,要是通过电脑参加视频会议就会更酸爽了。Ping包会出现大量丢包,时延可能也会出现几毫秒到几十毫秒的时延。当然也有可能时延没有变大特别多,仍然是几毫秒,这是因为交换机的缓存buffer太小了,上行口的发送队列溢出,把Ping包直接丢弃了。
F5G全光方案,1台GPON ONU的下行GE口下挂4台电脑。当1台电脑以接近1Gbps的速率往服务器上传文件时,其它3台电脑由于拥有100Mbps(保证带宽大小灵活可配)的保证带宽,仍然可以拥有良好的业务体验,不管是访问业务系统,还是浏览网页,仍然是流畅无比。也许有人会说GPON上行时1.25bps,对以太光方案有点不太公平。没关系,可以用两台电脑上传满1.25Gbps时,其它两台电脑再去进行其它业务,也是无比丝滑。
♢ 总 结 ♢
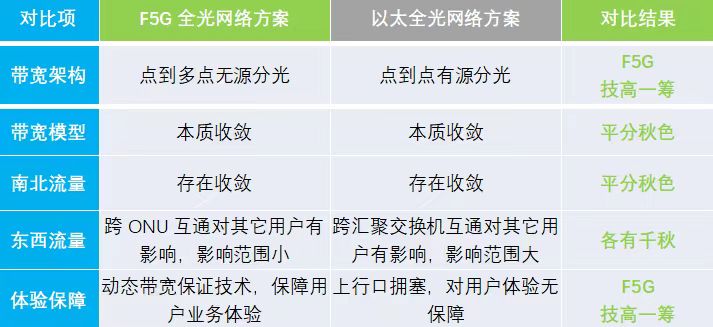
本文通过从带宽架构、带宽模型、南北流量、东西流量和体验保障等几个维度,客观地分析了F5G全光网络和以太全光网络在带宽上的对比,可以看出某些厂商对F5G全光的说法是错误的,F5G全光采用点到多点的无源分光技术,不仅可以满足园区各种东西流量、南北流量模型的应用场景,还能提供以太全光所不具备的用户端口级带宽保障技术,是最佳的低碳节能的全光方案。关于低碳节能,后续再详细介绍,按照相同的接入用户规模和带宽收敛模型,以太全光方案汇聚层(汇聚交换机)功耗,大约是F5G全光方案汇聚层(OLT)功耗的10倍以上。
如何开源实现中国区域和海外区域分流
工具:使用ipset和iptables
目标:国内外ip路由分流
过程:
使用 ipset 和 iptables 可以很方便地实现中国区域和海外区域的流量分流。下面是一个简单的配置示例:
首先,创建两个 ipset,一个用于存储中国区域的 IP 地址,另一个用于存储海外区域的 IP 地址。
ipset create china-ips hash:net
ipset create overseas-ips hash:net
然后,将中国区域和海外区域的 IP 地址添加到相应的 ipset 中。可以从公开的 IP 地址数据库或者第三方提供的 IP 地址列表中获取这些 IP 地址。
ipset add china-ips 1.0.1.0/24
ipset add china-ips 1.0.2.0/24
# 将其他中国区域的 IP 地址添加到 china-ips 中
# 添加海外区域 IP 地址到 overseas-ips 中
接下来,可以使用 iptables 规则来根据 ipset 中的地址列表对流量进行分流。
# 分流中国区域的流量
iptables -A PREROUTING -t mangle -m set –match-set china-ips src -j MARK –set-mark 0×1
# 分流海外区域的流量
iptables -A PREROUTING -t mangle -m set –match-set overseas-ips src -j MARK –set-mark 0×2
# 添加路由规则,将标记为 0×1 的流量路由到中国区域的网关,将标记为 0×2 的流量路由到海外区域的网关
ip rule add fwmark 0×1 table 100
ip route add default via <china-gateway> table 100
ip rule add fwmark 0×2 table 200
ip route add default via <overseas-gateway> table 200
以上示例中,china-gateway 是中国区域的网关,overseas-gateway 是海外区域的网关。这样配置后,根据 IP 地址的归属区域,流量将被分流到不同的网关。需要根据实际网络环境和需求进行适当的调整和配置。
mikrotik上做cn区域ip分流
MikroTik 路由器上配置中国区域 IP 分流可以使用地址列表和路由规则来实现。以下是一个简单的规则设置示例:
-
创建地址列表: 首先,需要创建一个地址列表,其中包含中国区域的 IP 地址范围。可以在 MikroTik 的 IP 地址列表中创建一个地址列表,列出所有中国区域的 IP 地址范围。
/ip firewall address-list add list=china address=1.0.1.0/24 # 请根据实际情况添加中国 IP 地址范围 add list=china address=1.0.2.0/24 ... -
创建路由规则: 接下来,需要创建路由规则来分流中国区域的流量。可以使用防火墙过滤规则和路由规则来分流流量。
/ip firewall mangle add chain=prerouting src-address-list=china action=mark-routing new-routing-mark=china-traffic /ip route add dst-address=0.0.0.0/0 routing-mark=china-traffic gateway=china-gateway
在上述示例中,china-traffic 是一个自定义的路由标记,china-gateway 是中国区域的外部网关。这样配置后,所有匹配中国 IP 地址列表的流量将被标记并分流到中国区域的外部网关。
需要根据实际网络环境和需求进行适当的调整和配置。建议在配置规则前进行充分的备份,以避免配置错误造成网络中断。
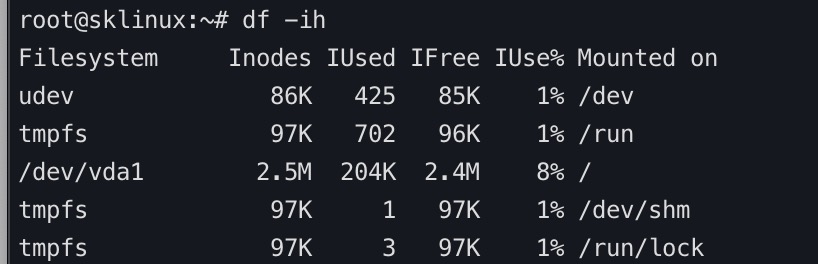
linux文件系统inode使用耗尽的一次故障处理
故障现象:
1.无法启动php-fpm
2.无法启动mysql
3.网站无法访问
分析思路:
1.查看磁盘容量,服务运行情况
2.查看inodoe使用情况
排查过程:
1.容量正常
2.端口运行不正常,php服务 mysql服务为启动,启动失败
3.检查inode发现使用率100%
问题分析:
当 ext4 文件系统中的 inode 使用率达到 100% 时,表示系统已经使用完了所有的 inode。即使磁盘空间还有剩余,由于没有空闲的 inode,就无法创建新的文件或目录。要处理这个问题,可以按照以下步骤进行:
检查当前的 inode 使用情况: 可以使用 df -i 命令来检查当前文件系统的 inode 使用情况。找到 inode 使用量已经达到 100% 的文件系统。
找出占用大量 inode 的目录: 使用 df -i 命令查看 inode 使用情况后,可以进入占用 inode 较多的目录,然后使用以下命令找出占用大量 inode 的文件或目录:
find /path/to/directory -xdev -printf ‘%h\n’ | sort | uniq -c | sort -k 1 -n
清理不必要的文件或目录: 根据上一步骤找出的占用 inode 较多的文件或目录,可以进行清理,删除不必要的文件或目录来释放 inode。
考虑重新分配 inode: 如果上述清理操作后仍然无法解决问题,可以考虑重新创建文件系统并分配更多的 inode。在新创建文件系统时,可以通过 mke2fs 命令的 -N 选项来指定分配更多的 inode。
请注意,在处理 inode 使用率达到 100% 的问题时,一定要谨慎操作,确保不删除重要的文件或目录,且备份好需要保留的数据。
istio-ingress-sds的一些障碍绕行方法
1.通过官网的by step 使用ingress-gateway发布ssl始终不成功,但是ingress-gateway的http服务暴露ok。
2.决定使用曲线救援方法,在外侧通过nginx来发布tls,内部回源使用http,但是遇见了http 426的错误。
➜ ~ curl https://192.168.1.25:443/ -H “Host: uat.sklinux.com” -i -k -v
* Trying 192.168.1.25…
* TCP_NODELAY set
* Connected to 192.168.1.25 (192.168.1.25) port 443 (#0)
* WARNING: disabling hostname validation also disables SNI.
* TLS 1.2 connection using TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256
* Server certificate: *.uat.sklinux.com
* Server certificate: Fishdrowned ROOT CA
> GET / HTTP/1.1
> Host: uat.sklinux.com
> User-Agent: curl/7.54.0
> Accept: */*
>
< HTTP/1.1 426 Upgrade Required
HTTP/1.1 426 Upgrade Required
< Server: nginx
Server: nginx
< Date: Mon, 27 May 2019 02:25:25 GMT
Date: Mon, 27 May 2019 02:25:25 GMT
< Content-Length: 0
Content-Length: 0
< Connection: keep-alive
Connection: keep-alive
经查原因为:
nginx 反向代理默认走的http 1.0版本
但是 被反向代理的服务器是1.1版本的!
所以在反向代理的时候加上一句:proxy_http_version 1.1;
即可!
但是最终通过SDS进行tls服务发布还没彻底解决,这个问题将持续跟进社区。
kubernetes-1.14安装
1.所有节点安装docker、kubelet、kubeadm、kubectl
curl -fsSL https://get.docker.com | bash -s docker –mirror Aliyun
curl https://mirrors.aliyun.com/kubernetes/apt/doc/apt-key.gpg | apt-key add -
cat << EOF > /etc/apt/sources.list.d/kubernetes.list
deb https://mirrors.aliyun.com/kubernetes/apt/ kubernetes-xenial main
EOF
apt-get update
apt-get install -y kubelet kubeadm kubectl
2.在master和node节点拉取海外docker镜像
kubeadm config images list列出所需要img:
k8s.gcr.io/kube-apiserver:v1.14.0
k8s.gcr.io/kube-controller-manager:v1.14.0
k8s.gcr.io/kube-scheduler:v1.14.0
k8s.gcr.io/kube-proxy:v1.14.0
k8s.gcr.io/pause:3.1
k8s.gcr.io/etcd:3.3.10
k8s.gcr.io/coredns:1.3.1
3.master上初始化
kubeadm init
初始化成功后你会看见如下提示
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
You should now deploy a pod network to the cluster.
Run “kubectl apply -f [podnetwork].yaml” with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.0.20:6443 –token 8sio7q.g6cj9m15c0ev3d9b \
–discovery-token-ca-cert-hash sha256:81fc89c762536cadc9580278bd12fe14933ead5d9bdf5b5b1a9c07f0a3084958
4.node加入集群
kubeadm join 192.168.0.20:6443 –token 8sio7q.g6cj9m15c0ev3d9b \
–discovery-token-ca-cert-hash sha256:81fc89c762536cadc9580278bd12fe14933ead5d9bdf5b5b1a9c07f0a3084958
即可
5.coredns可能运行有问题,是因为网络还不是覆盖网络
需要安装
https://docs.projectcalico.org/v3.6/getting-started/kubernetes/installation/hosted/kubernetes-datastore/calico-networking/1.7/calico.yaml
修改里面cidr方面的参数然后创建应用 @master上
6.安装完成
NAME STATUS ROLES AGE VERSION
node20 Ready master 9d v1.14.0
node21 Ready <none> 9d v1.14.0
node22 Ready <none> 7d22h v1.14.0
aws-vpc简介
Amazon VPC (Virtual Private Cloud) 是AWS的网络基础设施。使用VPC服务可以在AWS中创建一个独立隔离的网络,在这个隔离的网络空间中可以创建任何AWS资源,例如EC2、Redis、RDS数据库等等,VPC网络使这些AWS资源互相连接,传递数据,并且提供外网访问的网关。
VPC和子网(Subnet)
当新建一个VPC,需要为虚拟网络定义IP地址范围作为CIDR地址,例如CIDR为10.1.0.0/16。IPv4的CIDR可以手动指定,但是IPv6的CIDR只能由AWS自动分配。
CIDR(无类别域间路由,Classless Inter-Domain Routing)将IP地址按照前缀分成一组,使用一种无类别的域际路由选择算法,大大减少了路由表维护的条目数。
VPC的IP地址段可以进一步划分IP段,从而创建子网(Subnet)。一个VPC横跨多个可用区(Availability Zone),但是一个子网只能位于一个可用区里面。 继续阅读
zabbix监控RouteOS
zabbix on docker
1.使用镜像zabbix/zabbix-server-mysql:latest
该镜像功能如下
支持mysql数据库的zabbix server
zabbix-server-mysql – Zabbix server with MySQL database support
暴露zabbix-server端口10051
2.运行zabbix-server
docker run –name some-zabbix-server-mysql \
-e DB_SERVER_HOST=”some-mysql-server” \
-e MYSQL_USER=”some-user” \
-e MYSQL_PASSWORD=”some-password” \
-itd –restart=’always’ \
-p 10051:10051 \
zabbix/zabbix-server-mysql:tag
3.运行zabbix管理页面后台
镜像:zabbix/zabbix-web-nginx-mysql
docker run –name some-zabbix-web-nginx-mysql \
-e DB_SERVER_HOST=”some-mysql-server” \
-e MYSQL_USER=”some-user” \
-e MYSQL_PASSWORD=”some-password” \
-e ZBX_SERVER_HOST=”some-zabbix-server” \
-e PHP_TZ=”some-timezone” \
-itd \
或者其他的一些参数
zabbix/zabbix-web-nginx-mysql:tag
4.后台添加设备
ip:161
5.关联模板 为 Template Net Mikrotik SNMPv2
下载地址:https://share.zabbix.com/network_devices/mikrotik/template-net-mikrotik-snmpv2
6.修改发现策略
7.展示流量图

quagga-rip实现容器跨主机通信
跨主机容器手工解决方法
1.zebra
2.rip or ospf or bgp
效果:

docker rip