Ansible常用模块
Ansible通过模块的方式来完成一些远程的管理工作。可以通过ansible-doc -l查看所有模块,可以使用ansible-doc -s module来查看某个模块的参数,也可以使用ansible-doc help module来查看该模块更详细的信息。下面列出一些常用的模块:
1. setup
可以用来查看远程主机的一些基本信息:
ansible -i /etc/ansible/hosts test -m setup
Ansible常用模块
Ansible通过模块的方式来完成一些远程的管理工作。可以通过ansible-doc -l查看所有模块,可以使用ansible-doc -s module来查看某个模块的参数,也可以使用ansible-doc help module来查看该模块更详细的信息。下面列出一些常用的模块:
1. setup
可以用来查看远程主机的一些基本信息:
ansible -i /etc/ansible/hosts test -m setup
在项目迭代的过程中,不可避免需要”上线“。上线对应着部署,或者重新部署;部署对应着修改;修改则意味着风险。
目前有很多用于部署的技术,有的简单,有的复杂;有的得停机,有的不需要停机即可完成部署。本文笔者简单讨论一下目前比较流行的几种部署方案,或者说策略。如有不足之处请指出,如有谬误,请指正^_^。 继续阅读
就像我们在自己电脑上搭建了一个论坛的网站,应用程序(例如Apache服务器)、数据库等都部署在我们自己的电脑上的。就可以正常运行了。
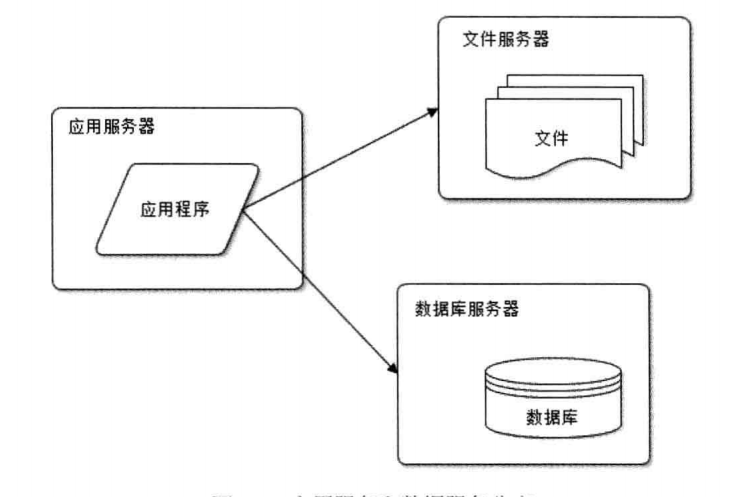
我们的论坛越来越受欢迎,用户越来越多,论坛也十分越活。但是面临的问题是数据库中的信息越来越多,存储不够了。这个时候我们又多弄了几台服务器,应用程序(Apache服务器)、数据库和保存用户上传的文件(图片)单独部署在不同的服务器上。
应用服务器处理大量的业务逻辑,所以需要更好的CPU
数据库服务器需要完成数据的快速查询,所以需要更大的硬盘和内存
文件服务器保存用户上传的图片等文件,所以需要更大的硬盘
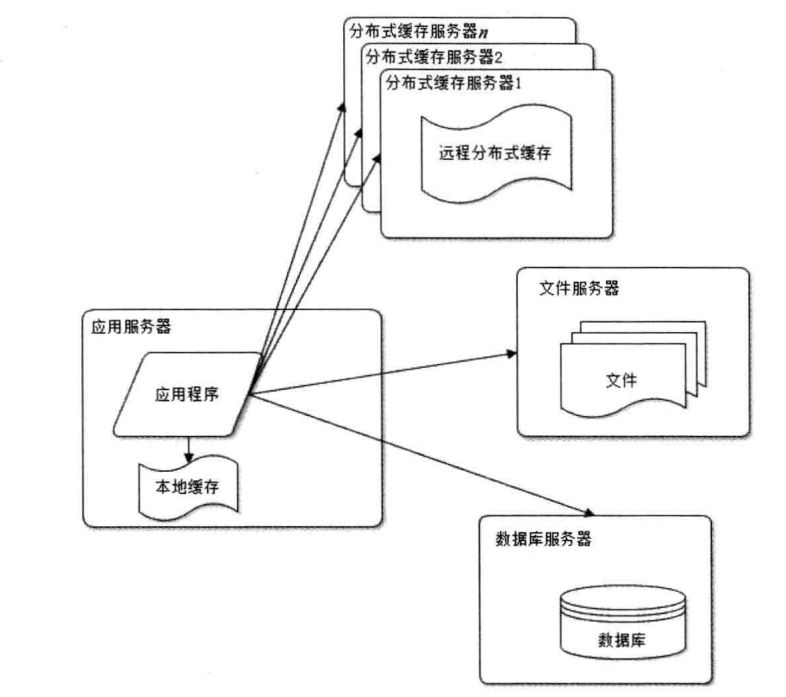
我们的论坛用户继续快速增涨,我们发现访问速度越来越慢,原因就是很多请求都要访问数据库(例如,读取用户的个人信息,打个不恰当的比喻,每次进入一个话题,该话题中的每一个发言用户的信息都要从数据库中读取)。这个时候如果我们能缓存这些用户信息,每次从缓存中读取,这样对数据库的压力会大大降低,并且读取的性能也提升了很多。
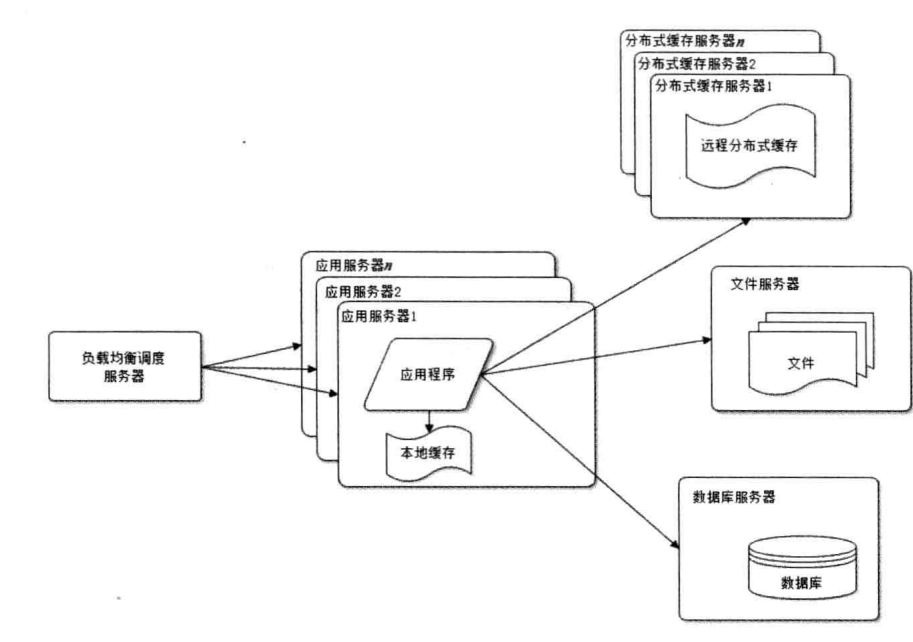
使用缓存后,又出现问题了,在论坛使用高峰的时候,单一应用服务器处理请求连接有限,这个时候就需要部署应用服务器集群,然后在使用一个负载均衡服务器(例如Nginx,apache Server)。
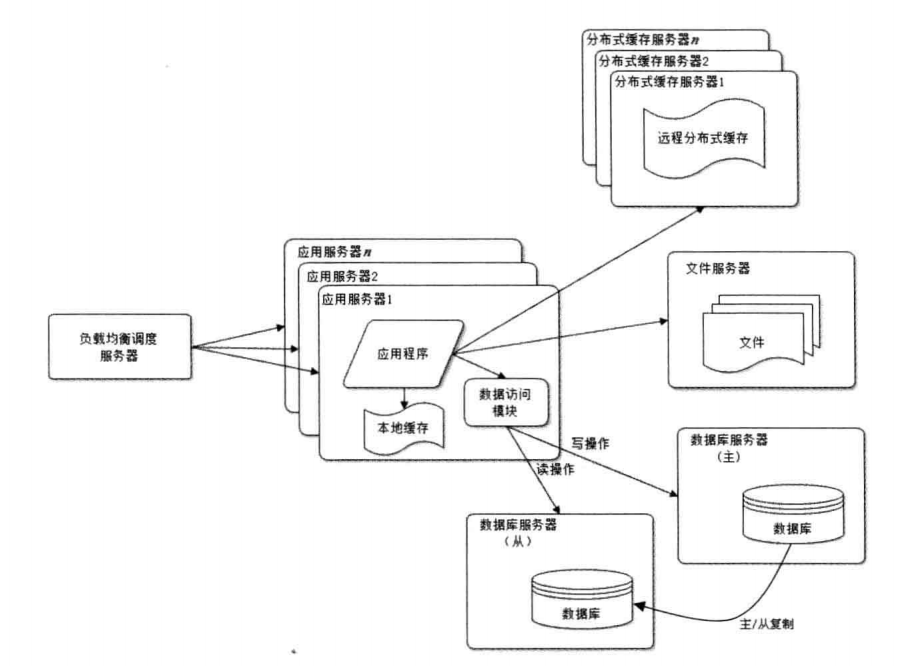
用户继续增加,使用缓存后,虽然大部分读的操作都不会直接访问数据库,但是还是有一些读操作(缓存未命中,缓存过期)和全部的写操作还是必须操作数据库。当用户达到一定规模,数据库又成了系统的性能瓶颈。
在原来单一数据库的模式上,设置一个主数据库和从数据库,写操作的时候写入主数据库,然后从主数据库同步到从数据库中。读操作就在从数据库中读。当然我们需要一个数据访问的模块来处理这些逻辑
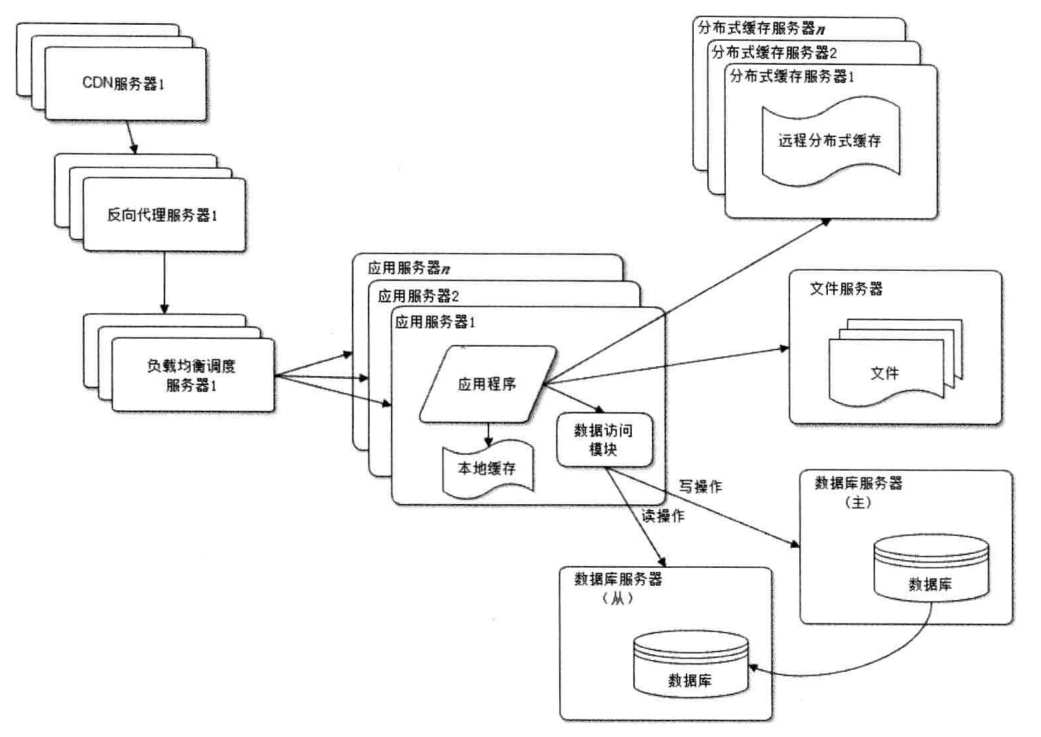
论坛用户反应,打开你们的论坛速度太慢了,再不改善我就不用了。
原因也很简单,一个访问请求中,也许存在很多静态资源(CSS,图片)等,又或者用户的使用的联通,我们的服务器在电信。适应反向代理和CDN技术可以大大改善用户请求的响应速度
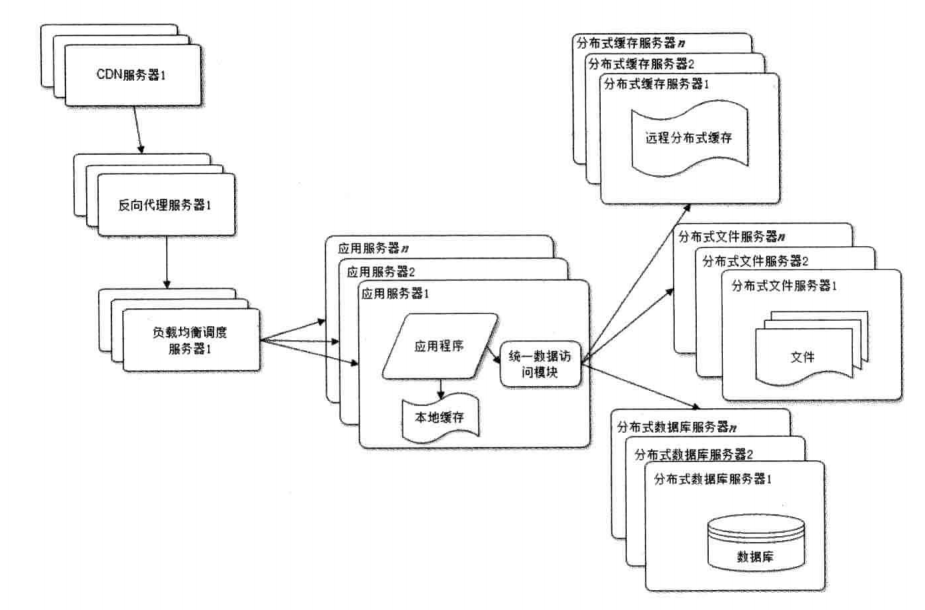
虽然数据库进行读写分离以后,但是在我们论坛疯狂增涨下,任何强大的单一服务器的性能都是有限的,只有使用分布式系统,才能在业务不断增涨进行横向扩展。这个是我们最后手段了,使用之前应该先考虑能否根据业务不同来拆分数据库。例如我们论坛的包括了不同主题(汽车、房子、以及你懂的话题),如果按照这些主题来区分数据库,也是好的选择。(注意这个虽然也是要使用多个数据库,但和分布式数据库的概念是有很大区别的)
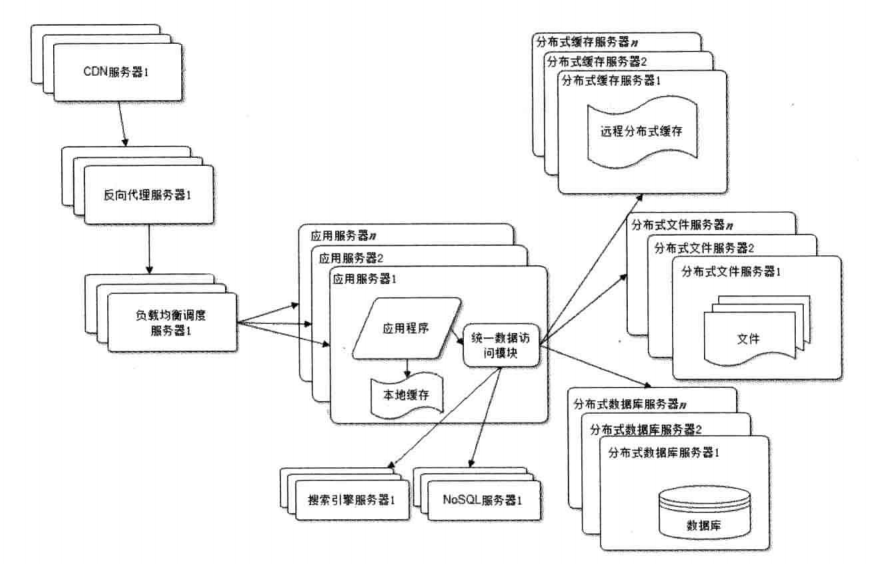
论坛中,要搜索一些帖子,如果每次进行数据库查询,在数据量十分大的情况,显然是不可取的。还有就是对数据存储的要求,需要使用搜索引擎(例如lucene)。
NoSql主要是对一些特殊需求的数据进行存储,例如配置信息可以放redis中(也算是缓存),日志信息可以存储在Hbase上等等。
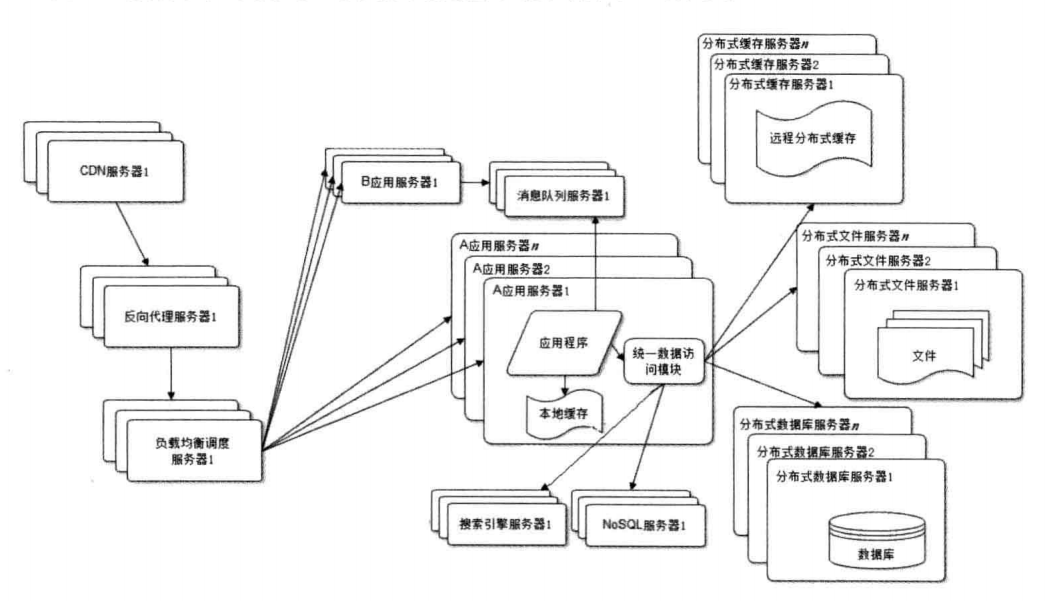
为了以后以后的发展,我们的业务需要扩展,我们需要增加即时通讯的业务(类似微信),知识问答(类似知乎)。但是这些业务是分开开发的,如果和原有的论坛业务耦合在一起,在代码发布的时候,就会十分麻烦。这个时候,根据不同的业务,分别进行部署和发布。
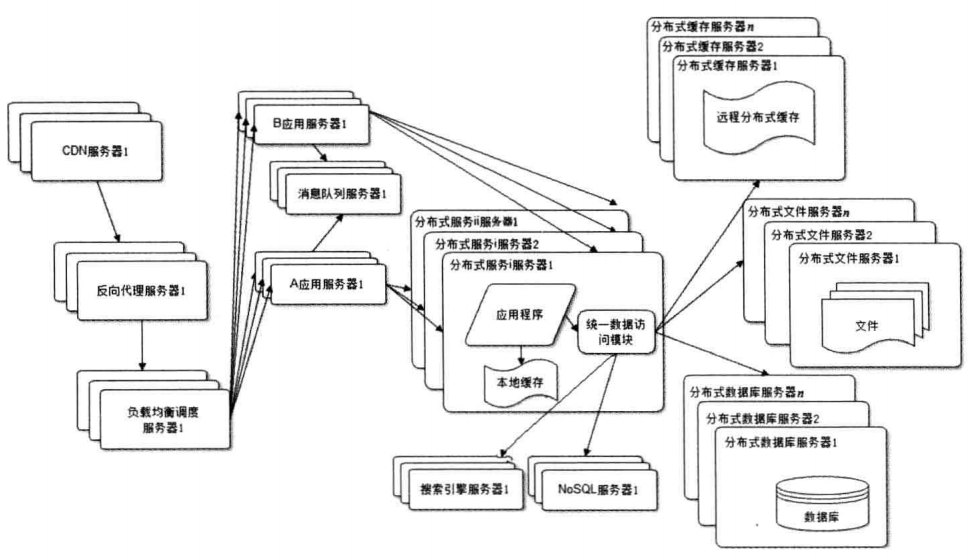
虽然按照业务进行拆分以后,虽然不同业务之间的管理隔离开来,但是问题又出现了,但我们部署了上万台服务器的时候,每个服务器都保持有与数据库的连接,这样会导致数据集的连接资源不够。而且还有个问题就是对一些基础功能每个业务之间有重复开发的问题。
所以,我们把一些基础业务功能提取出来,做成基础服务独立部署(登录服务、用户信息管理,日志功能等)。这样上层只用关系自己的业务逻辑,调用底层统一的基础服务。
在早期的计算机领域,限流技术(time limiting)被用作控制网络接口收发通信数据的速率。 可以用来优化性能,减少延迟和提高带宽等。 现在在互联网领域,也借鉴了这个概念, 用来为服务控制请求的速率, 如果双十一的限流, 12306的抢票等。 即使在细粒度的软件架构中,也有类似的概念。
两种常用算法
令牌桶(Token Bucket)和漏桶(leaky bucket)是 最常用的两种限流的算法。
漏桶算法
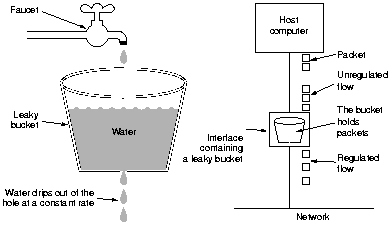
它的主要目的是控制数据注入到网络的速率,平滑网络上的突发流量。漏桶算法提供了一种机制,通过它,突发流量可以被整形以便为网络提供一个稳定的流量。 漏桶可以看作是一个带有常量服务时间的单服务器队列,如果漏桶(包缓存)溢出,那么数据包会被丢弃。 用说人话的讲:
漏桶算法思路很简单,水(数据或者请求)先进入到漏桶里,漏桶以一定的速度出水,当水流入速度过大会直接溢出,可以看出漏桶算法能强行限制数据的传输速率。
在某些情况下,漏桶算法不能够有效地使用网络资源。因为漏桶的漏出速率是固定的参数,所以,即使网络中不存在资源冲突(没有发生拥塞),漏桶算法也不能使某一个单独的流突发到端口速率。因此,漏桶算法对于存在突发特性的流量来说缺乏效率。而令牌桶算法则能够满足这些具有突发特性的流量。通常,漏桶算法与令牌桶算法可以结合起来为网络流量提供更大的控制。
令牌桶算法
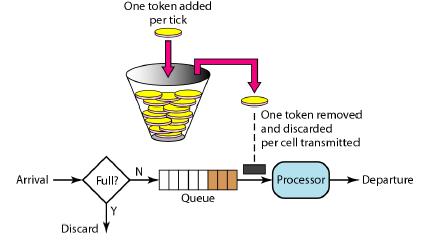
令牌桶算法的原理是系统会以一个恒定的速度往桶里放入令牌,而如果请求需要被处理,则需要先从桶里获取一个令牌,当桶里没有令牌可取时,则拒绝服务。 令牌桶的另外一个好处是可以方便的改变速度。 一旦需要提高速率,则按需提高放入桶中的令牌的速率。 一般会定时(比如100毫秒)往桶中增加一定数量的令牌, 有些变种算法则实时的计算应该增加的令牌的数量, 比如华为的专利”采用令牌漏桶进行报文限流的方法“(CN 1536815 A),提供了一种动态计算可用令牌数的方法, 相比其它定时增加令牌的方法, 它只在收到一个报文后,计算该报文与前一报文到来的时间间隔内向令牌漏桶内注入的令牌数, 并计算判断桶内的令牌数是否满足传送该报文的要求。
从最终用户访问安全的角度看,设想有人想暴力碰撞网站的用户密码;或者有人攻击某个很耗费资源的接口;或者有人想从某个接口大量抓取数据。大部分人都知道应该增加 Rate limiting,做请求频率限制。从安全角度,这个可能也是大部分能想到,但不一定去做的薄弱环节。
从整个架构的稳定性角度看,一般 SOA 架构的每个接口的有限资源的情况下,所能提供的单位时间服务能力是有限的。假如超过服务能力,一般会造成整个接口服务停顿,或者应用 Crash,或者带来连锁反应,将延迟传递给服务调用方造成整个系统的服务能力丧失。有必要在服务能力超限的情况下 Fail Fast。
另外,根据排队论,由于 API 接口服务具有延迟随着请求量提升迅速提升的特点,为了保证 SLA 的低延迟,需要控制单位时间的请求量。这也是 Little’s law 所说的。
还有,公开 API 接口服务,Rate limiting 应该是一个必备的功能,否则公开的接口不知道哪一天就会被服务调用方有意无意的打垮。
所以,提供资源能够支撑的服务,将过载请求快速抛弃对整个系统架构的稳定性非常重要。这就要求在应用层实现 Rate limiting 限制。
limit_req_zone $binary_remote_addr zone=one:10m rate=1r/s;
server {
location /search/ {
limit_req zone=one burst=5;
}
详细参见: ngx_http_limit_req_module
详细参见: Haproxy Rate limit 模块
RateLimiters是令牌桶和漏桶在.NET 中实现。这些策略可用于速率限制请求不同的网站中,后端或 API 调用等场景。
ASP.NET Web API rate limiter for IIS and Owin hosting
这个在 Redis 官方文档有非常详细的实现。一般适用于所有类型的应用,比如 PHP、Python 等等。Redis 的实现方式可以支持分布式服务的访问频率的集中控制。Redis 的频率限制实现方式还适用于在应用中无法状态保存状态的场景。
网上有众多关于这方面的文章,这里列出了本文参考的一些文档。
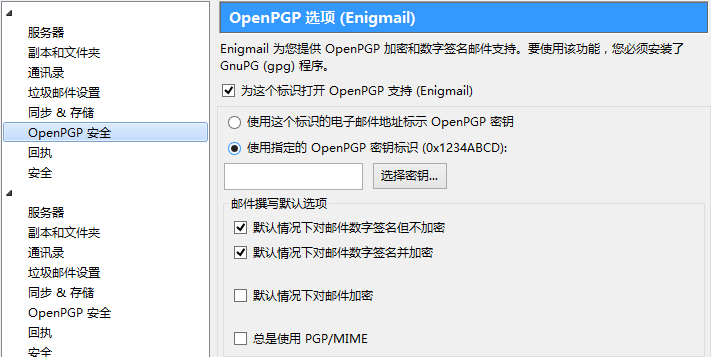
一、添加插件Enigmail

二、进行密钥管理,并创建->新密钥对
三、选择账户,选择有无密码,创建密钥。根据提示选择是否要撤销文件。
选择无密码创建密钥对速度快。最好选择生成撤销证书,在以后密钥对无用时告诉密钥服务器撤销无效公钥。
四、上传公钥,更新公钥,并为邮箱指定密钥
如果出现错误:Please ensure that you have a valid OpenPGP key, and that your account settings point to that key.
到账户设置指定邮箱的密钥:
SRE是Site Reliability Engineer的简称,从名字可以看出Google的SRE不只是做Operation方面的工作,更多是保障整个Google服务的稳定性。SWE是SoftWare Egineer的简称,即软件工程师(负责软件服务的开发、测试、发布)。SWE更新的程序代码(下文称为server),只有在SRE同意后才能上线发布。因此,SRE在Google工程师团队中地位非常高!
SRE是Site Reliability Engineer的简称,从名字可以看出Google的SRE不只是做Operation方面的工作,更多是保障整个Google服务的稳定性。SWE是SoftWare Egineer的简称,即软件工程师(负责软件服务的开发、测试、发布)。SWE更新的程序代码(下文称为server),只有在SRE同意后才能上线发布。因此,SRE在Google工程师团队中地位非常高!

王璞,数人科技创始人。2002年获得北京航空航天大学力学学士学位,2007年获得北京大学计算机硕士学位,2011年获得美国George Mason University计算机博士学位,研究方向机器学习,发表十余篇机器学习以及数据挖掘相关论文。毕业后在硅谷先后供职StumbleUpon、Groupon和Google三家公司,负责海量数据处理、分布式计算以及大规模机器学习相关工作。2014年回国创办数人科技,基于Mesos和Docker构建分布式计算平台,为企业客户提供高性能分布式PaaS解决方案。
SRE是Site Reliability Engineer的简称,从名字可以看出Google的SRE不只是做Operation方面的工作,更多是保障整个Google服务的稳定性。SRE不接触底层硬件如服务器,这也是高逼格的由来:
Google 数据中心的硬件层面的维护工作是交给technician来做的,technician一般不需要有大学学历。
SWE是SoftWare Egineer的简称,即软件工程师(负责软件服务的开发、测试、发布)。
SWE更新的程序代码(下文称为server),只有在SRE同意后才能上线发布。因此,SRE在Google工程师团队中地位非常高!我们下面将分别介绍。
备注:我本人是SWE,本文是从SWE的角度看SRE,我的老朋友@孙宇聪同学是原Google SRE,他会从另一个角度来阐述此主题,敬请期待哦!
SRE在Google不负责某个服务的上线、部署,SRE主要是保障服务的可靠性和性能,同时负责数据中心资源分配,为重要服务预留资源。
如上文所受,和SRE想对应的是SWE(软件开发工程师),负责具体的开发工作。
举个例子,我之前在Google的互联网广告部门,我们team负责的server是收集用户数据用于广告精准投放,这个server的开发、测试、上线部署等工作,都是由SWE来完成。
SRE不负责server的具体实现,SRE主要负责在server出现宕机等紧急事故时,做出快速响应,尽快恢复server,减少服务掉线带来的损失。
备注:这里的server是指服务器端程序,而不是物理服务器。在Google,SWE和SRE都无权接触物理服务器。
因为SRE的职责是保障服务的稳定和性能,所以在SRE接手某个server之前,对server的性能和稳定性都有一定的要求,比如server出现报警的次数不能超过一定的频率,server对CPU、内存的消耗不能超过预设的指标。
只有server完全满足SRE的要求以后,SRE才会接手这个server:
当server出现问题时,SRE会先紧急修复,恢复服务,然后SRE会和SWE沟通,最终SWE来彻底修复server的bug。
同时,对server的重大更新,SWE都要提前通知SRE,做好各种准备工作,才能发布新版server:
为了能让SRE能接手server,SWE要根据SRE的要求,对server做大量的调优。首先SRE会给出各种性能指标,比如,服务响应延迟、资源使用量等等,再者SRE会要求SWE给出一些server评测结果,诸如压力测试结果、端到端测试结果等等,同时,SRE也会帮助SWE做一些性能问题排查。
所以SRE在Google地位很高,SWE为了让server成功上线,都想法跟SRE保持好关系。
我举个具体的例子来说明,在Google,SWE是如何跟SRE配合工作来上线server的。
我们team对所负责的server进行了代码重构,重构之后,要经过SRE同意,才能够上线重构后的server。
为此,我们team的SWE要向SRE证明,重构后的server对资源的开销没有增加,即CPU、内存、硬盘、带宽消耗没有增加,重构后的server性能没有降低,即端到端服务响应延迟、QPS、对压力测试的响应等这些性能指标没有降低:
当时对server代码重构之后,server有个性能指标一直达不到SRE的要求。这个指标是contention,也就是多线程情况下,对竞争资源的等待延迟。重构server之后,contention这项指标变得很高,说明多线程情况下,对竞争资源的等待变长。
我们排查很久找不到具体原因,因为SWE没有在代码中显式使用很多mutex,然后请SRE出面帮忙。
SRE使用Google内部的图形化profiling工具,cpprof,帮我们查找原因。
找到两个方面的原因:
简而言之,Google的SRE不是做底层硬件维护,而是负责Google各种服务的性能和稳定性。换句话说,Google的SRE保证软件层面的性能和稳定性,包括软件基础构架和应用服务。
SRE需要对Google内部各种软件基础构架(Infrastructure)非常了解,而且SRE一般具有很强的排查问题、debug、快速恢复server的能力。
我列举一些常见的Google软件基础构架的例子:
Google还有更多的软件基础构架系统:Megastore、Spanner、Mustang等等,我没有用过,所以不熟悉。
我个人觉得,在云计算时代,运维工程师会慢慢向Google的SRE这种角色发展,远离底层硬件,更多靠近软件基础架构层面,帮助企业客户打造强大的软件基础构架。
企业客户有了强大的软件基础构架以后,能够更好应对业务的复杂多变的需求,帮助企业客户快速发展业务。
另外我个人观点,为什么Google的产品给人感觉技术含量高?
并不见得是Google的SWE比其他Microsoft、LinkedIn、Facebook的工程师能力强多少,主要是因为Google的软件基础构架(详见上文)非常强大,有了很强大的基础构架,再做出强大的产品就很方便了。
Google内部各种软件基础构架,基本上满足了各种常见分布式功能需求,极大地方便了SWE做业务开发。
换句话说,在Google做开发,SWE基本上是专注业务逻辑,应用服务系统(server)的性能主要由底层软件基础构架来保证。
————我是分割线————
下面就是本次分享的互动环节整理(真的非常精彩哦:)。
问题1:SRE参与软件基础项目的开发吗?
SRE一般不做开发。比如Google的BigTable有专门的开发团队,也有专门的SRE团队保障BigTable server的性能和稳定性。
问题2:一般运维工具,或者监控,告警工具,哪个团队开发?
SRE用的大型管理工具应该是专门的团队开发,比如Borgmon是Google的监控报警工具,很复杂,应该是专门的团队开发,SRE会大量使用Borgmon。
问题3:基础软件架构有可以参考的开源产品吗?
Google内部常见的软件基础构架都有开源对应的版本,比如Zookeeper对应Chubby,HDFS对应Google File System,HBase对应BigTable,Hadoop对应MapReduce,等等。
问题4:还有SRE会约束一些项目的性能指标,比如CPU和内存的使用阈值,这些值是从哪里得来的?或者说根据哪些规则来定制的?
SRE负责Google的数据中心资源分配,所以一些重要server的资源是SRE预留分配好的。对CPU、内存等资源的分配,SRE按照历史经验以及server的业务增长预期来制定。
此外Google数据中心里运行的任务有优先级,高优先级的任务会抢占低优先级任务的资源,重要的server一般优先级很高,离线任务优先级比较低,个人开发测试任务优先级最低。
nginx支持在线播放mp4
1.安装nginx时加参数
–prefix=/opt/nginx –with-http_gzip_static_module –with-http_flv_module –with-http_mp4_module
2.匹配处理
location ~* .*.mp4$ {
mp4;
}
3.mime类型增加
video/mp4 mp4;
chrome就直接支持访问mp4的url直接播放了。
目前市面上很多移动端加速产品。但是都是基于sdk这种,然后劫持请求回边缘CDN节点。做链路加速,这种产品在一定程度并不能加速你的移动app。
我们的最佳实践是抛弃dns请求,全部使用ip,然后通过高速链路、高质量的BGP节点进行数据获取。在移动端,如果你放一个http://www.sklinux.com/1.jpg的请求,那么移动端会首先请求www.sklinux.com的dns解析。
然而,在移动网络非常复杂的今天,dns劫持是非常正常的事情。再加之dns解析时间太长,体验很慢也在情理之中。
然而市面上也有这种加速解析的方案,比如httpdns。但是httpdns,虽然加快了dns的解析,但是不是真正的走的去域名化道路。
所以,我们抛弃了域名。拥抱回归了ip的直接请求方式。比如:http://ip/1.jpg 那么问题来了,多个业务域名需要单ip路由
我们需要在nginx进行上进行业务区分,然后路由回源。这样就可以了,目前这种方案可以支持http、https。网络连通性效果非常的不错
希望做移动端app的研发、运维人员可以考虑。这种方案的连通性可以提升移动端的用户体验,移动端性能提升90%左右。
效果非常好!在这里分享给大家,共勉!
论高可用的“妙”处
在互联网行业中高可用,目前看来有三种用法。分别是:
1.业务量的增加后,由于市场的需要必须保障核心业务的稳定性。我在这里把称之为 “正常”模式。
2.业务量根本还没有,而且还是新上项目。但是由于服务的启动导致时间的延长(上分钟不能提供服务),所以要做多节点部署
要用前端的高可用,来解决这种程序不能立马提供服务的问题。这种我在这里称之为“斗比”模式。
3.平台不差钱,流量和业务都没有增加也没有接入前。就考虑了高可用。多节点这种,我在这里称之为“高富帅”模式
正常模式,我在这里不谈论。因为市场决定一切、核心服务的强需求,理所当然的。今天的我的观点主要在斗比模式的高可用。
斗比模式的高可用有几个问题。
由于服务的这种延迟启动,导致必须要借用“高可用”的“斗比”模式来进行解决了。比如下面的流程:
1.由于服务的启动时长,不能及时的提供服务。在部署的时候,需要发布成多节点。
需要在升级的时候,先要在摘掉负载均衡上第一个斗比节点。然后升级,升级启动几分钟的时间内,由于服务本身还未启动。然而tomcat(这里指某个基于tomcat的一些java业务服务)
端口已经启动,显然这个时候不能将节点放入负载均衡。那么将进入几分钟漫长的等待(这个时候千万要祈祷java线程别崩溃)后,验证日志ok后再将节点加入负载均衡。并让
节点服务能在负载均衡生效。
2.在升级第2个斗比节点的时候,如法炮制。
针对这种斗比模式,本人有如下观点:
1.这种模式是坑运维和坑老板
2.这种模式是用运维工具去弥补程序设计的严重缺陷
3.这种模式是给平台化、自动化一杯毒酒
4.这种模式是用高可用、灰度这种“正常”模式来装高逼格,用装高逼格的方法论来掩饰程序设计上的缺陷。
技术团队如何有效沟通?请看实例
a:@运维b、@运维c,现在我们的qps峰值是多少?
b:请问什么项目的qps的峰值?什么对象的峰值?
a:你们有哪些对象?
b:(b开始不计成本的开始给a罗列项目)xxx项目、xx项目、xxxx项目……
a:那就看xx项目的吧(随机指定1个)
b:你要看xx项目的什么对象的峰值(a去找数据,不计成本帮a找)
a:有哪些对象?(很悠闲的姿态)
b:有xx的、有xxx的、有xxxx的等等等等(罗列对象)
a:那就看xxx的吧(随机指定1个)
b:xxx的qps峰值为xxx(开始翻数据)
a:好的,谢谢!
我们现在统计下a和b的成本
a的成本是
a:@运维b、@运维c,现在我们的qps峰值是多少?
a:你们有哪些对象?
a:那就看xx项目的吧(随机指定1个)
a:有哪些对象?(很悠闲的姿态)
a:那就看xxx的吧(随机指定1个)
a:好的,谢谢!
总共就5句话
b的成本为5个事件。包括列表、筛选、询问最后解答
b:请问什么项目的qps的峰值?什么对象的峰值?
b:(b开始不计成本的开始给a罗列项目)xxx项目、xx项目、xxxx项目……
b:你要看xx项目的什么对象的峰值(a去找数据,不计成本帮a找)
b:有xx的、有xxx的、有xxxx的等等等等(罗列对象)
b:xxx的qps峰值为xxx(开始翻数据)
如何提问?
a为什么不能第一次就讲,我需要xx项目的xx对象的qps峰值?
导致b会去不断询问a,到底需要什么?